ISUCON12予選に「Railsへの執着はもはや煩悩(ry」で参加して予選通過しました
今年も@cnosukeさんと@aibouさん一緒に、「Railsへの執着はもはや煩悩の域であり、開発者一同は瞑想したほうがいいと思います。」というチームでISUCONの予選に出ました。
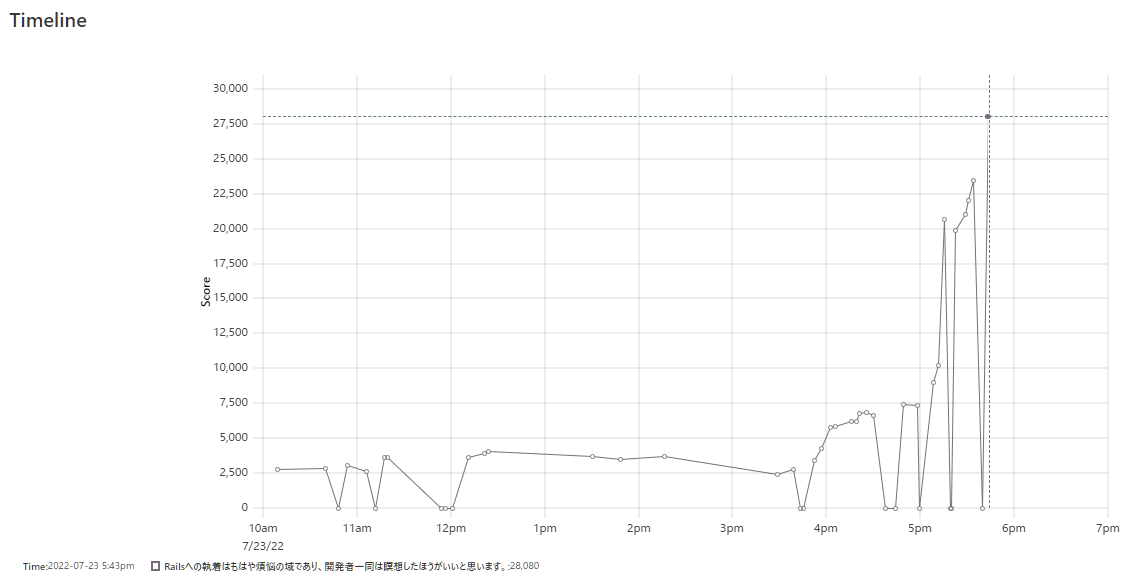
最終スコアは28,080点で、予選通過することができました。
一次募集も二次募集も一瞬で枠が埋まってしまい申込みに間に合わなかったので、出題を担当した回を除いてISUCON3から毎年出ていたISUCON参加がついに途切れてしまうかと思ってしまいましたが、なんとか追加募集の枠で参加することができました。
(追加募集の枠も3分くらいで埋まってしまったので本当に危なかった。。。)
ISUCON10, ISUCON11も同じメンバーで、そのときは予選1週間前くらいに練習していたのですが、今年はタイミングが合わずぶっつけ本番になってしまいました。
なんとなくの分担
cnosukeさんが主にアプリ改修とか、aibouさんがSQLite→MySQLのデータ移行やMySQLのインデックス周りとか、自分はデプロイとか細々とした作業をやる感じで、分担していました。
3年目ということもあって割りとスムーズに進められた気がします。
なんとなくのスケジュール
3人がやったこと全部を雑に書いてます。
| 時刻 | やったこと | メモ |
|---|---|---|
| 09:30 | 集合 | |
| 10:00 | 競技開始 | |
| 10:15 | とりあえず初期状態でベンチ回す | 2,800点くらいだった気がする |
| 10:30 | nginxとMySQLの設定ファイル群と、webappを、まるっとgitリポジトリに突っ込んだりした | /etc/mysqlにシンボリックリンクを張るようにしていたがうまく動いてくれなくなったので後でMySQLについてはgit管理を諦めた |
| 10:45 | コード読んだりkataribeを導入したりしてた | |
| 10:55 | 1号機をnginx, webapp, SQLiteに、2号機をMySQLに、3号機は使わない構成にして、破壊的な実験とかは3号機で試してもらうような状態にした | 特に大きく手を入れてなかったのでMySQLがめちゃくちゃCPUを食ってる状態になった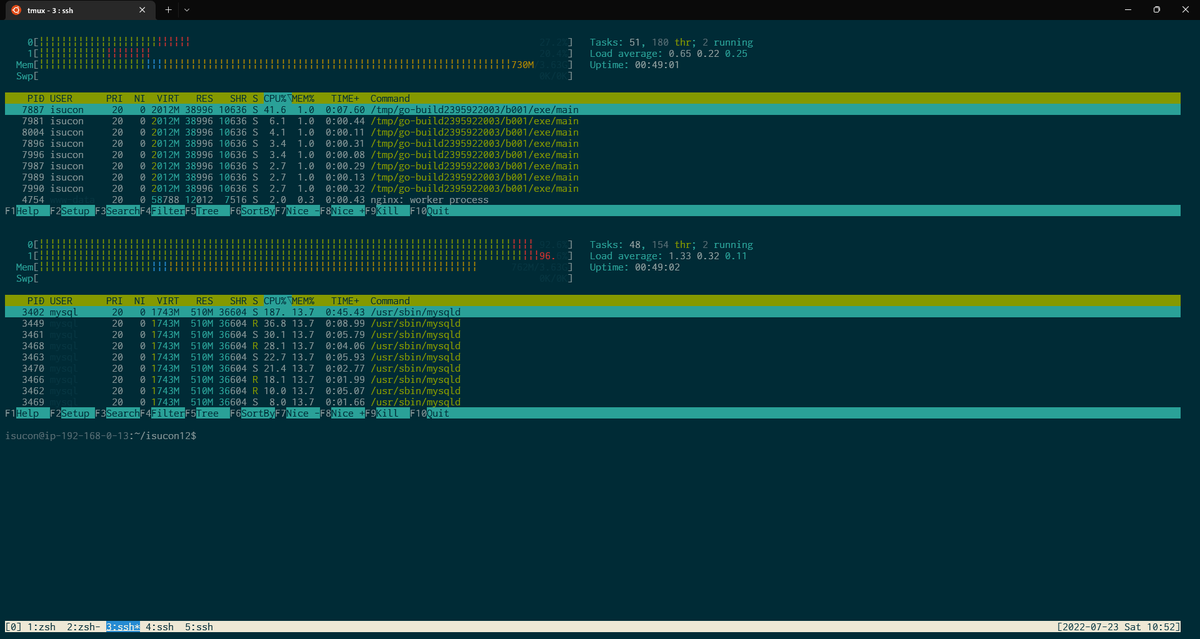 |
| 11:25 | MySQLにインデックスを張ったりしていた | |
| 13:50 | とにかく「GET /api/player/competition/:competition_id/ranking」が遅いことがわかったので対策を考え始める | |
| 15:10 | SQLiteに入ってたデータを全部MySQLにダンプして、SQLiteは全く使わない状態にした | 2,826点 |
| 15:55 | 採番ロジックが複雑そうに見えたのでULIDを使うように変更した | 4,267点 |
| 16:30 | 1号機をMySQLに、2号機をwebappに、3号機をnginxという構成にした | 7,469点 |
| 17:05 | いろいろキャッシュを入れたり地道に修正 | 10,234点 |
| 17:15 | SQLiteは捨てたのにflockしっぱなしだったのに気づいて修正 | 20,669点 1号機(MySQL)だけがとにかく重い状態になった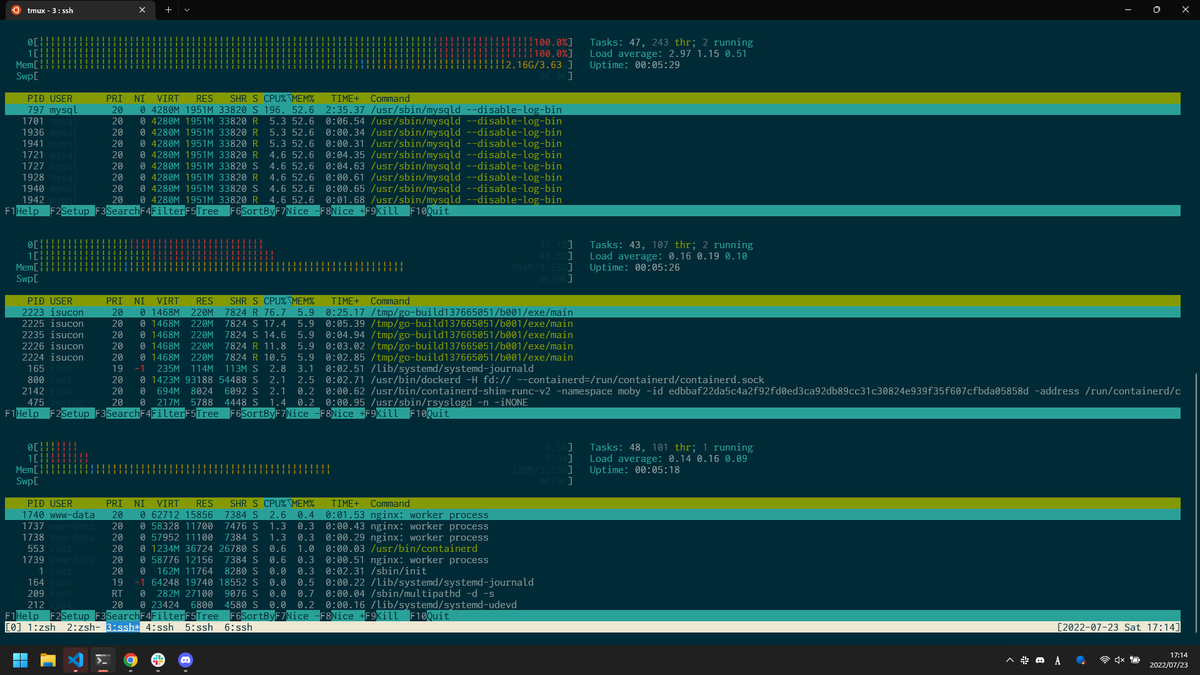 |
| 17:30 | 更にcompetition周りをキャッシュ化 | 22,037点 |
| 17:45 | インデックスを更に張ったり再起動試験したりしてたら更に上がったので、もうこれ以降は提出をやめることに | 28,080点 |
| 18:00 | 競技終了 |
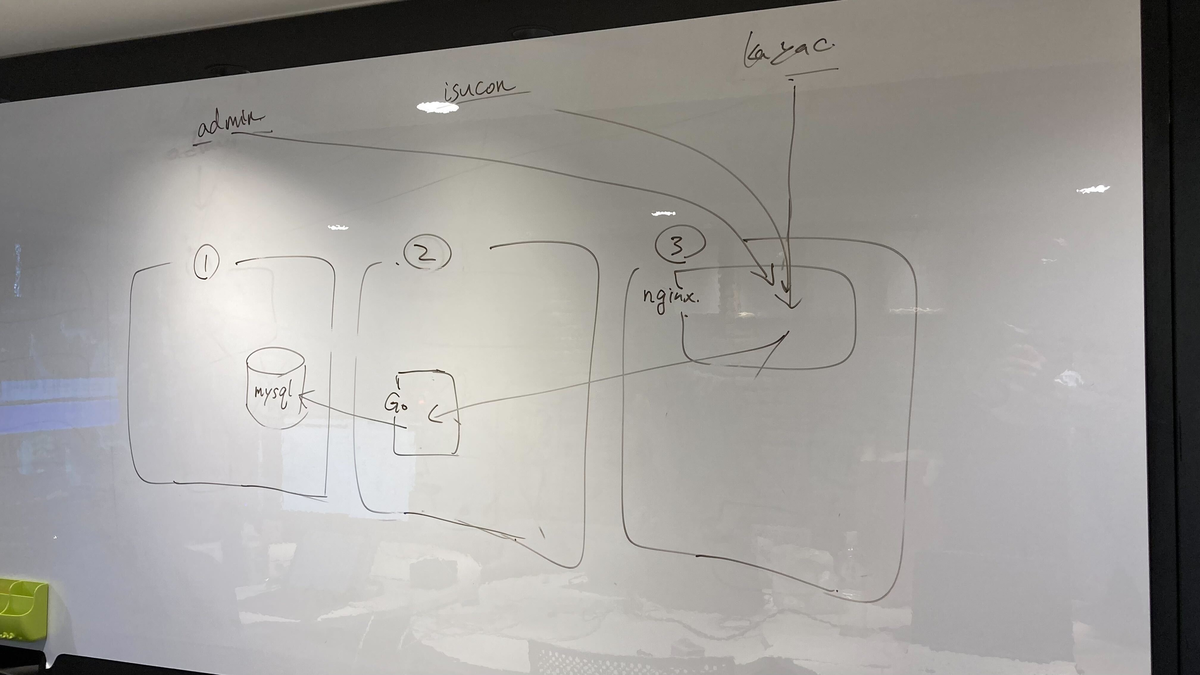
最終的な構成図
ベンチが詰まることもなく、その他のトラブルもなくとても快適な競技環境でありがたかったです。
運営の皆様、本当にありがとうございました!!
ISUCON7以来、5年ぶり3回目の本戦出場なので楽しみにしてます!!!!
ISUCON11予選に「Railsへの執着はもはや煩悩(ry」で参加したけどダメでした
今年も@cnosukeさんと@aibouさんと「Railsへの執着はもはや煩悩の域であり、開発者一同は瞑想したほうがいいと思います。」というチームでISUCONの予選に出ました。
3人とも別の会社にいるので、去年同様に前の週にリハーサルを行ってイメージを掴みました。
去年と同じようになんとなくの役割分担として、cnosukeさんがAPIのコード変更を行い、aibouさんがDB・nginx周りのチューニングを行い、自分はデプロイとか設定のgit管理したりと雑多な対応をしていました。
なんとなくのスケジュール
昼食を食べずにぶっ続けでやっていたのでかなり疲れてしまって、あんまり当日の記憶も残っていないのですごく雑です。
| 時刻 | やったこと | メモ |
|---|---|---|
| 09:40 | 集合 | |
| 10:00 | 競技開始 | |
| 10:11 | webapp以下をgitに突っ込む | |
| 10:29 | 1号機をnginx, アプリ、3号機をmariadbにする | これだけでちょっとスコアがった |
| 10:49 | いくつかmariadbにインデックスを貼った | 24,648点出て暫定2位になったのでテンションが上がった |
| 11:52 | /assets 以下はnginxが直接返すようにした |
|
| 11:59 | 秘蔵のmy.cnfを投入した | 実際は 設定ファイルのパーミッションがおかしかった せいで投入できていなかった… |
| 12:39 | /api と /initialize 以外は全部nginxが直接返すようにした |
|
| 13:05 | アプリのリファクタリングが終わった | |
| 13:23 | 1号機のCPUが辛いので /api/trend だけ2号機に流してみた |
|
| 16:02 | バルクインサートするようにアプリを書き換えた | 38,324点まで上がった |
| 16:24 | アプリを書き換えたり、更にmariadbにインデックスを張ったりした | この頃に最高得点の54,690点が出た |
| 17:13 | アプリを直したりmariadbにインデックスを貼ったりトラフィックを1号機と2号機で混ぜるようにしたりした | 36,926点までしか出なくて伸び悩む |
| 17:30 | ポータルがメンテに入ったので マシンを再起動 してみたり、細かなアプリケーションの改善とかをしてた | |
| 18:10 | ポータルがメンテ明けになったのでベンチを回してみたところ、なんと1,000点しか出なくなってしまった | とても焦った |
| 18:44 | nginxの設定がおかしいことに気づいたがもう時間がなくなってしまったので、1号機にnginxとアプリ、3号機にmariadbの構成で出した。 | 13,982点になってしまった |
競技中のトラブル
mariadbの設定が反映されていなかった件
/etc/mysql 以下をすべてgitリポジトリに突っ込んで、 /etc/mysql 自体はそのリポジトリのシンボリックリンクにしていたのですが、どうやらパーミッションがおかしい(本来はroot:rootが所有しているのが、isucon:isuconになっちゃった)のが原因で、実は設定が反映されていなかったことに途中で気づいて、気づいたものの対応するのにとても時間がかかってしまいました。
結局、AMIがあったので別のインスタンスを立てて、それの /etc/mysql の構成を真似て構築し直して、gitリポジトリに追加しないようにしたところ使えるように戻りました。
nginxの設定がおかしかった件
ポータルのメンテ後くらいからスコアが1,000点しか出なくなって、なんでだろう…とずっと考えていたのですが気づけず、ISUの「状態」が1行も出ず空っぽになっているのがおかしい?と気づいて、
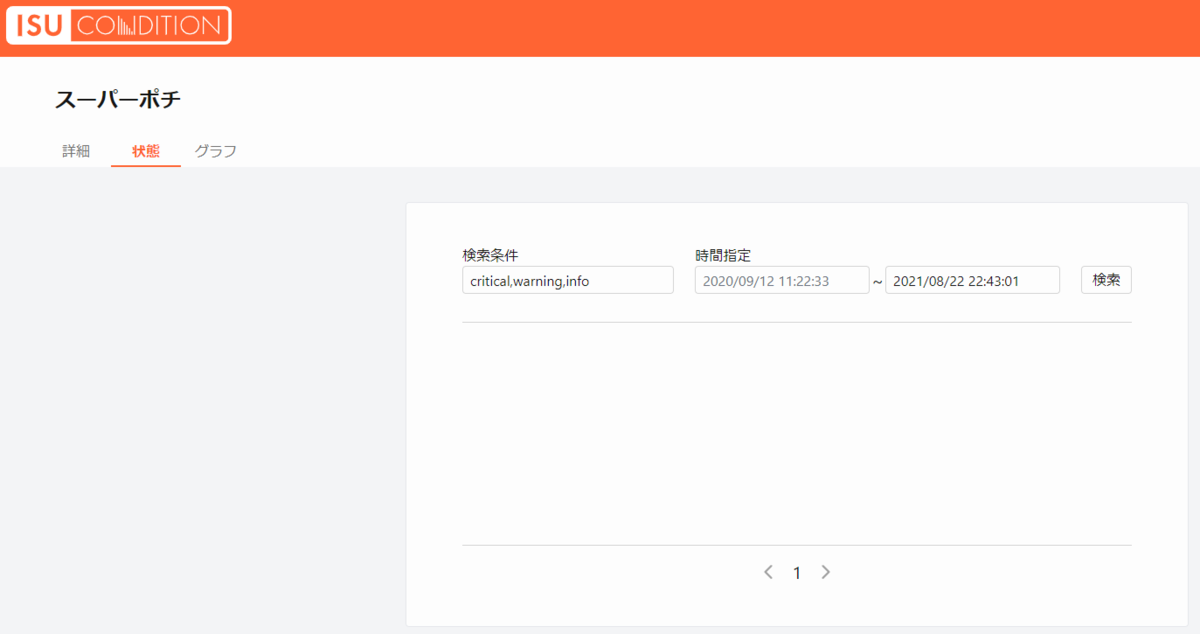
見てみたところ、自分が入れてしまったnginxの設定でIPアドレスを間違っていたのが原因でした。。。
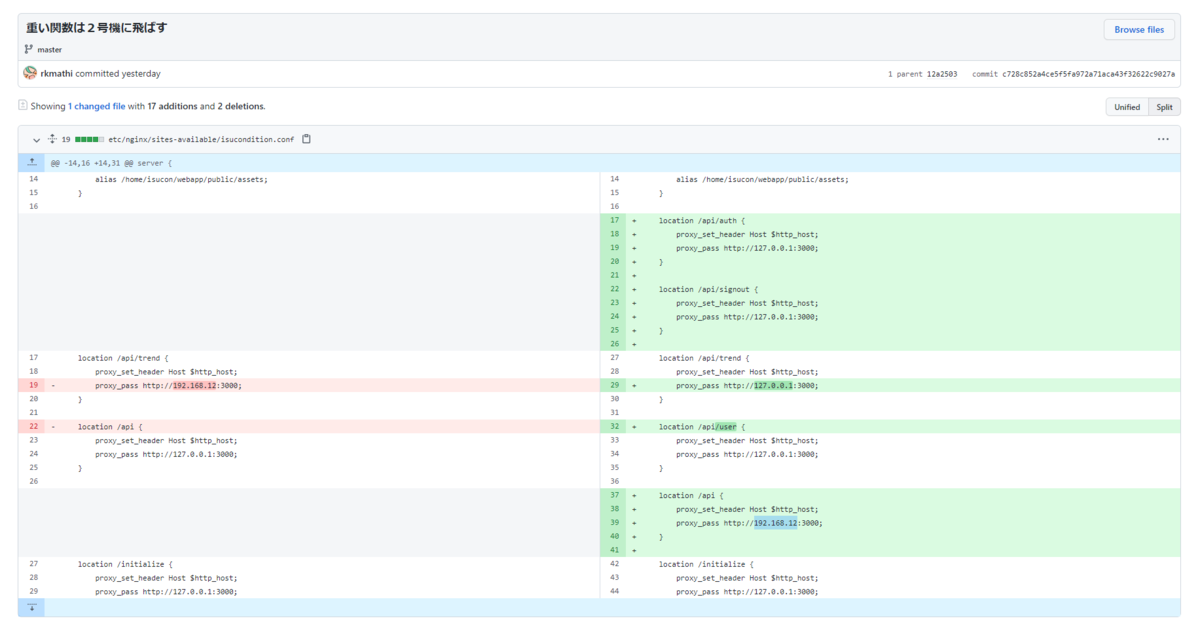
リクエストを飛ばす先がないのでエラーになるかなと思ったのですが、今回のルールでは減点にならなかったので、加点もされず減点もされず、どこがおかしいのか気づくのに時間がかかってしまったのがもったいなかったです。。。
予選突破には11万点くらい必要だったので届かなかったかもしれませんが、途中でトラブってしまったのがもったいなかったです(´;ω;`)
問題はとても面白かったし、ポータルも途中不具合があったもののそれ以外は快適に使えましたし、すごく楽しかったです。
来年こそ予選突破したい…!
Kustomizeでvarsの代わりにreplacementsを使う
Kustomize v3.8までなら、varsを使うことで次のように特定の箇所の値を別の箇所に上書きすることができ、例えば
# test.yaml --- apiVersion: v1 kind: Service metadata: name: test labels: app.kubernetes.io/name: THIS-IS-TEST-SERVICE-NAME # ☆この値を上書きに使いたい spec: type: NodePort ports: - nodePort: 32000 port: 80 selector: run: test --- apiVersion: v1 kind: Pod metadata: name: test labels: app.kubernetes.io/name: $(TEST_SERVICE_NAME) # ★ここを上書きする spec: containers: - name: nginx image: nginx env: - name: testenv value: $(TEST_SERVICE_NAME) # ★ここも上書きする
# kustomization.yaml resources: - test.yml vars: # ☆上書きに使う値の情報 - name: TEST_SERVICE_NAME objref: apiVersion: v1 kind: Service name: test fieldref: fieldpath: metadata.labels.[app.kubernetes.io/name]
というマニフェストファイル群に対してkustomize build .すると、次のように上書きすることができていた。
apiVersion: v1 kind: Service metadata: labels: app.kubernetes.io/name: THIS-IS-TEST-SERVICE-NAME # ☆この値を上書きに使う name: test spec: ports: - nodePort: 32000 port: 80 selector: run: test type: NodePort --- apiVersion: v1 kind: Pod metadata: labels: app.kubernetes.io/name: THIS-IS-TEST-SERVICE-NAME # ★上書きされた name: test spec: containers: - env: - name: testenv value: THIS-IS-TEST-SERVICE-NAME # ★上書きされた image: nginx name: nginx
しかし、Kustomize v3.9以降からはエラーになるようになってしまった。
Error: field specified in var '{TEST_SERVICE_NAME ~G_v1_Service {metadata.labels.[app.kubernetes.io/name]}}' not found in corresponding resource
どうやら、varsで指定するfieldpathに . が含まれているような場合について、解釈できなくなってしまったようだった。
もともと2020年1月くらいからvarsをこれ以上使い続けるのは…みたいなIssueもたっていて、
最近のKustomizeでは代替になるreplacementsという機能が実装されていたので、それを使ってみることにした。
※以降はKustomize v4.2.0で動作確認した
上に書いたような例をreplacementsで実現しようとすると、次のようになる。
# test.yaml --- apiVersion: v1 kind: Service metadata: name: test labels: app.kubernetes.io/name: THIS-IS-TEST-SERVICE-NAME # ☆この値を上書きに使う spec: type: NodePort ports: - nodePort: 32000 port: 80 selector: run: test --- apiVersion: v1 kind: Pod metadata: name: test labels: app.kubernetes.io/name: TO_BE_REPLACED # ★ここを上書きする (TO_BE_REPLACEDの部分は何でも良い) spec: containers: - name: nginx image: nginx env: - name: testenv value: TO_BE_REPLACED # ★ここも上書きする (TO_BE_REPLACEDの部分は何でも良い)
# kustomization.yaml resources: - test.yml replacements: - source: # ☆上書きに使う値の情報 version: v1 kind: Service name: test fieldPath: metadata.labels.[app.kubernetes.io/name] targets: # ★上書きされる対象の情報 - select: version: v1 kind: Pod name: test fieldPaths: - metadata.labels.[app.kubernetes.io/name] - spec.containers.0.env.0.value
こうしてkustomize build .を実行すると、冒頭に書いた例と同様に上書きされたマニフェストファイルが生成される。
varsの場合と異なり、「上書きに使う値」「上書きされる対象」のどちらのパスも明記する必要があるので若干めんどくさくなったように思ったが、よく言えば「どの部分が上書きされてしまうのか?」が一覧できるようになったので、慣れればreplacementsのほうが管理しやすくなるのかもしれない。
おうちKubernetesクラスタを組む(後編)
の続き。
ノートPC↔デスクトップマシンの通信があんまり安定してくれなくて、たまにパケットが通らなくなったりしてよく分からない感じになっちゃったので、VMからまるっと作り直した。 ただ、作り直してもたま~にパケットが通らなくなってしまうのが起きてしまったので、ルータをちゃんとしたヤツに買い換えないといけないのかもしれない。
Serviceの公開ができるようにする
k8sクラスタ上のPodに対してノートPCからどうやってアクセスするのがいいかな~と考えていたが、Serviceをtype: NodePortで作成するのが一番ラクだと思ったのでそうすることにした。
# nginxのPodをたてる $ kubectl run nginx --image=nginx # type: NodePortなServiceを作成する $ kubectl expose po nginx --name=nginx --type=NodePort --port=80 # 作成したPodがどのNodeで動いているか確認する $ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx 1/1 Running 0 13h 172.16.168.135 node1 <none> <none> # 作成したServiceのnodePortを確認する $ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx NodePort 10.104.230.33 <none> 80:30953/TCP 11m
これで「今回作成したnginxはnode1の30953ポートで動いている」ということが分かるので、そこにアクセスすれば見えた。
# node1のIPは192.168.10.191 $ curl -is http://192.168.10.191:30953 | head -2 HTTP/1.1 200 OK Server: nginx/1.21.0
しかしtype: NodePort(かつexternalTrafficPolicy: Cluster)の場合は、PodがいないNodeに対してアクセスしてしまっても正しいNodeに転送してくれるはずだったのに、なぜか転送されなかった。
# node2のIPは192.168.10.192 $ curl -is http://192.168.10.192:30953 | head -2 (返事がない)
調べてみると、Calicoを使ってかつ、KubernetesクラスタのCIDRをVMのと別のにしてしまうと、うまく転送してくれないとというようなIssueがあったので、その現象にあたってしまったのかもしれない?
Calicoではなく別のCNIプラグインなら大丈夫らしいので、試しにCiliumに切り替えてみたところ、うまく動いてくれたのでそっちを使うことにした。
Tailscaleで家の外からもk8sクラスタにアクセスできるようにする
次は家の外からでもアクセスしたいな~と思ったので、またまたsuperbrothersさんのを参考にして、Tailscaleを導入してみた。
アカウントを作成したら、クライアントを各マシンにインストールしただけで、本当にあっさり導入できてしまった。

iPhoneにTailscaleのクライアントを入れたら、4G回線からも普通に接続できてしまった。

TailscaleのMagic DNSを有効にする
Magic DNSを有効にすれば、「<マシン名>.<ユーザ名>.beta.tailscale.net」という名前で引けるようになるので、IPアドレスを覚えたり/etc/hostsに書いたりをせずに済むようになったため更に便利になった。

さっきはIPアドレスでアクセスしていたnginxのNodePortの例も、
$ curl http://node0.<アカウント名>.beta.tailscale.net:30953/ $ curl http://node1.<アカウント名>.beta.tailscale.net:30953/ $ curl http://node2.<アカウント名>.beta.tailscale.net:30953/
のようにFQDNでアクセスできるようになった。
また、kubernetes-dashboardについても
apiVersion: v1 kind: Service metadata: name: kubernetes-dashboard-expose namespace: kubernetes-dashboard spec: type: NodePort selector: k8s-app: kubernetes-dashboard ports: - nodePort: 30000 port: 443 targetPort: 8443 protocol: TCP
というようなtype: NodePortなServiceを作ることで、
$ curl http://node0.<アカウント名>.beta.tailscale.net:30000/ $ curl http://node1.<アカウント名>.beta.tailscale.net:30000/ $ curl http://node2.<アカウント名>.beta.tailscale.net:30000/
でアクセスできるようになった。

証明書を設定できていないので警告は出てしまうが。。。
最終的にはこういう感じになった。

これで一通り準備ができてそれっぽく使えるようになったので、Kubernetesクラスタで色々実験するのが捗りそう😺
あとTailscaleはすごい!!
おうちKubernetesクラスタを組む(前編)
いままで手元でKubernetes関連のなにかを試そうとすると、基本的にはThinkPad X390(Core i7-8665U 4コア8スレッド, メモリ16GB)のWindowsのWSL2上でkindを起動していたが、WSL2にメモリを12GB当ててしまうとWindowsが使う分が足りなくなってきたり、ノートPCなのでスリープしたりすると復帰時にたまにヘンになったりとあまり快適な状態ではなかったため、superbrothersさんのを参考に小さいデスクトップマシンを買ってみた。
デスクトップマシンの構成
小さめのマシンでいくつか迷ったけど、折角(?)なので使ったことがないRyzenを積んでるASUS Mini PC PN51にしてみた。 CPUはRyzen 5 5500UなのでノートPC用のだけど、基本電源はつけっぱなしにするつもりだったので消費電力が小さそうだし筐体サイズも小さいのでこれで十分かなということにした。
これだけではSSDもメモリもないので、Western Digital WD Blue SN550 NVMe SSD (1TB)と、Crucial CT16G4SFD832A x 2本を買ったので、構成はこうなった。
| 項目 | 中身 |
|---|---|
| CPU | Ryzen 5 5500U (6コア12スレッド) |
| メモリ | 32GB |
| SSD | 1TB |
| OS | Ubuntu Desktop 20.04 |
メモリは32GBか64GBかで迷ったけど、VMはいくつか立ち上げるつもりはあるものの、ゲームをするわけでもなく基本SSHかRDP経由で軽くGUIを使くらいの予定なので、32GBでいいやということにした。
消費税と送料込みで、
| 商品 | 値段 |
|---|---|
| PN51 | 47,700円 |
| WDS100T2B0C | 12,248円 (セールしてた) |
| CT16G4SFD832A x 2本 | 19,040円 |
| 合計 | 78,988円 |
と結構安く済んでよかった。 (価格ドットコムの価格推移をみた感じだと、もうちょっと前ならメモリもSSDも更に安く買えたかもしれないが…)
とりあえずKubernetesを動かす
家で使っているのは普通の家庭用Wi-fiルータなのであまり機能がないが、DHCP固定割当設定はあるのでそれでIPを固定することにして、SSHやRDPするときに迷わないようにした。
まずはvirt-managerを使って、Control Plane用に1つ(2core, 2GB)、Worker Node用に2つ(2core, 4GB)、Ubuntu ServerのVMを立ち上げた。
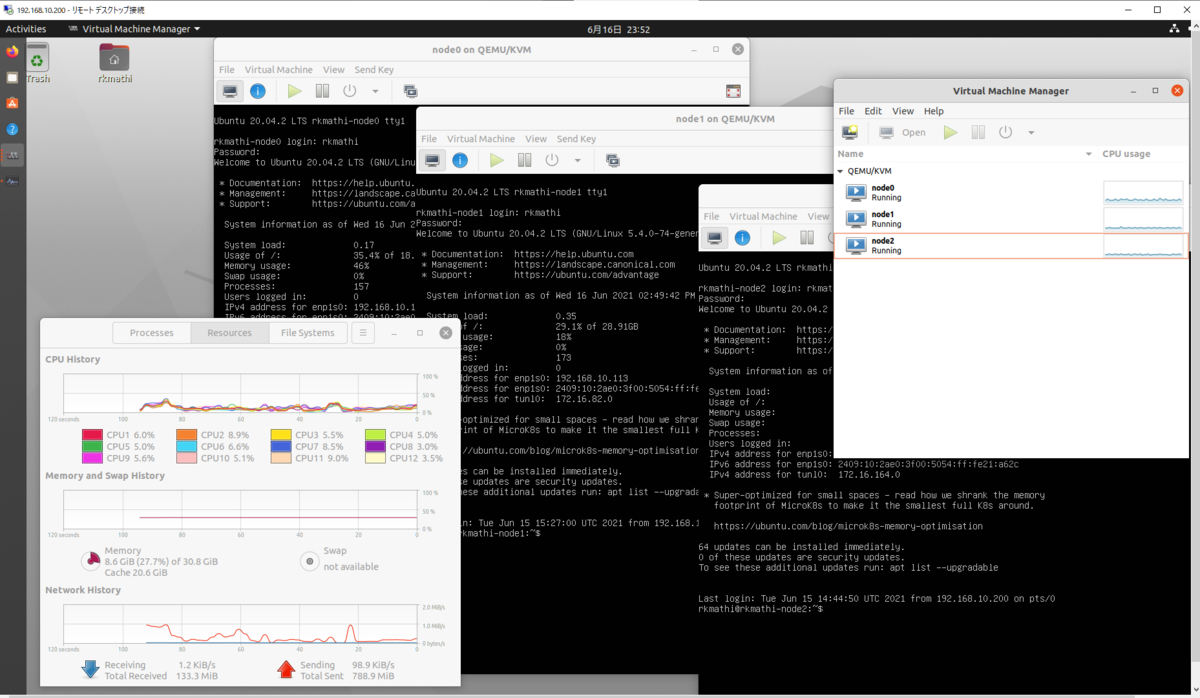
(いままで使ったことはないが)containerdをインストールして、kubeadmを使ってクラスタを起動して、CalicoをインストールしてReadyにするところまでできた。

その後、kubernetes-dashboardを起動させてみたが、ノートPCのWebブラウザから見ようとすると
- kubernetes-dashboardを
--kubelet-insecure-tlsオプション付きで起動させる。 - デスクトップマシン上で
kubectl proxy --address 0.0.0.0 --accept-hosts='^*$'を実行する。 - ノートPC上で
ssh -L 18001:<デスクトップマシンのIP>:8001 rkmathi@<デスクトップマシンのIP>を実行する。 - ノートPC上のWebブラウザで
http://localhost:18001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/#/loginにアクセスする。
というように面倒かつ安全じゃない感じの手順が必要になってしまったので、今まであまり触れてこなかったネットワーク周りを勉強しながらいい感じに直したい。
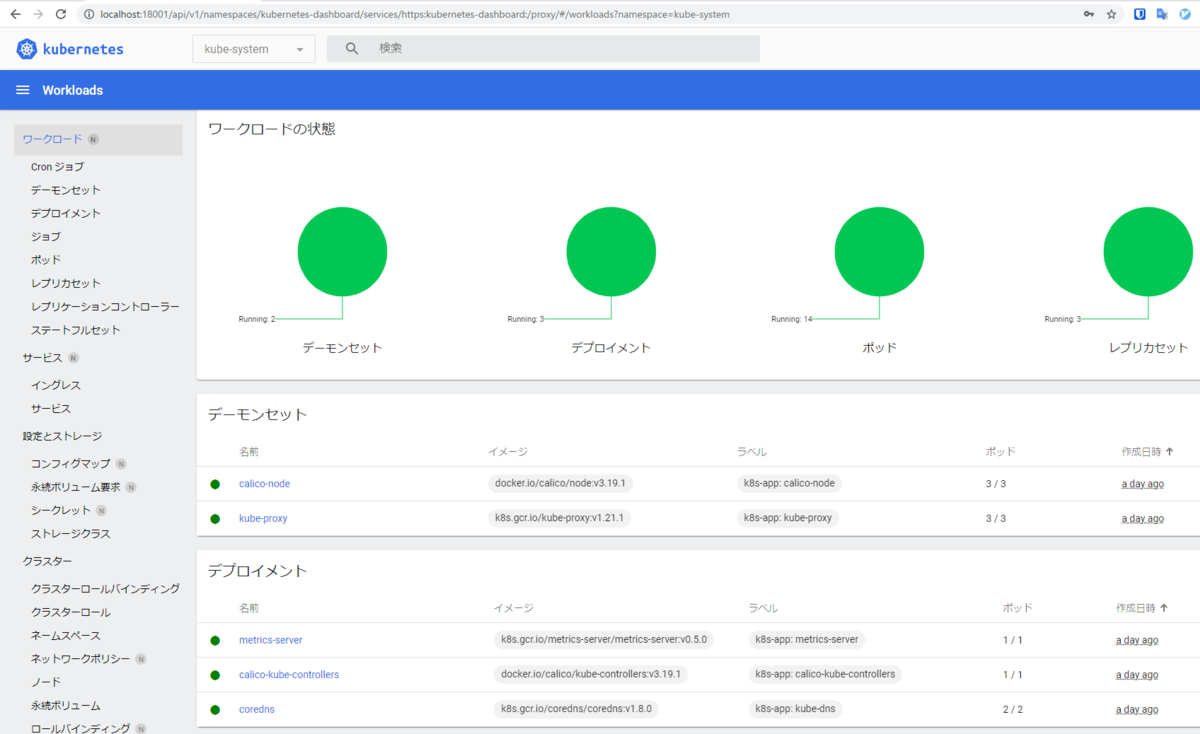
まずは↓のように家の中のノートPC経由でKubernetes上で動かしているWebアプリにアクセスできるようにしたいが、DNSとかMetalLBとかTLS周りとかがよくわかってないので色々試行錯誤中なので、後編に続く。。。
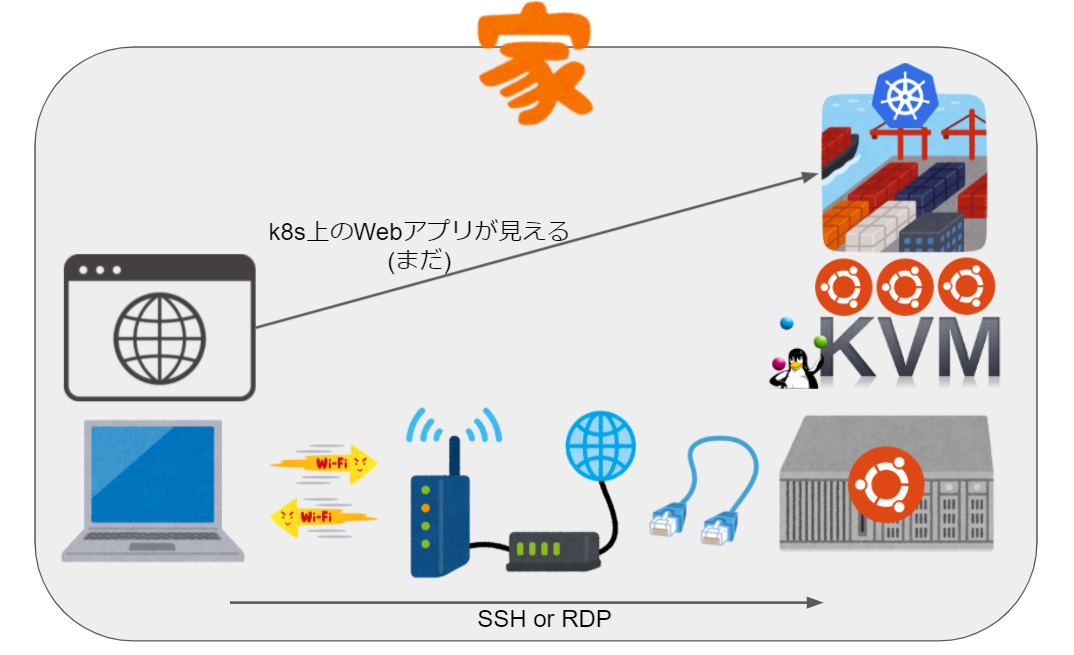
これができたら家の外からもつなげるようにしたい。
続き