Podのresourcesで指定するcpuの値について
Podのresourcesで指定する値で、cpuは具体的に何がどう制限されるのかがよく分かってなかったので調べてみた。
よく分からない部分
resources: requests: cpu: 100m # 100ミリってことは多分0.1コア以上確保できないWorker Nodeにデプロイされないんだろう memory: 256Mi # メモリを256Mi以上確保できないWorker Nodeにデプロイされないんだろう limits: cpu: 1000m # 1000ミリってことは1コア分ってことなんだろうけど、それを超えてCPUを使うとどうなるの? memory: 512Mi # メモリを512Mi以上消費したらコンテナがOOMKillerに殺される
という感じで resources.limits.cpu が意味する値の意味がよく分かっていなかった。
resources.requests.cpuも同様によく分かっていなかったが、requestsは「デプロイ先のWorker Nodeにはこれくらいの余裕が必要ですというよ指定」なんだろうなという理解だったので、あまり気にしていなかった。
resources.requests.cpuとresources.limits.cpuの単位の意味
resources.requests.cpuとresources.limits.cpuで指定する値は、「CPUのミリコア」で間違っていなさそうだった。
例えばキャパシティが4コアのWorker Nodeに対しては、合計で4000mよりも多くのresources.requests.cpuをスケジュールすることができない。
Worker Nodeの物理的なCPU1コア(ハイパースレッディングが有効なら論理1コア)が1000mに対応するので、新しいCPUだろうと古いCPUだろうと、1000mはおなじ量だということが分かった。
ということは、Worker Nodeに複数種類のCPUを混ぜてしまうとややこしいことになりそう?
resources.limits.cpuの値の意味
これは、そのコンテナが1秒間に専有できる最大のCPUの量だった。
つまり、1000mなら1コアを1秒間すべて専有するくらいCPUを消費することができ、500mなら1コアを1秒間のうち500ミリ秒までしか専有できない。
2500mなら、1コアを1秒間で2500ミリ秒だけ専有できるので、大体2.5コア分くらいのCPUを専有することができる。
また、resources.limits.cpuはresources.limits.memoryとは異なり、圧縮可能(compressible)なリミットであることが分かった。
そのため、キャパシティを超えてCPUを消費してしまったとしてもコンテナが殺されるようなことはなく、CPUの使用量が減らされるだけだった。
(今回の話とは全く関係ないが、)resources.requestsやresources.limitsで指定する値は普通に使う場合はcpuかmemoryだけしか指定しないが、Device Pluginという仕組みを使うと、たとえばGPUなど特殊なリソースのリクエストやリミットを制限するための仕組みを用意することができるらしい。
CPUを空回しするコンテナをresources.limits.cpuを変えて比較してみた
すごく単純だけど、次のような「ひたすらカウンタをインクリメントし続けて、1秒に1回だけ現在のカウント値を出力する」というプログラムを書いて、resources.limits.cpuを変えたPodで実行して性能を比較してみた。
package main import ( "log" "runtime" "sync" "time" ) const tryTimes = 10 var mux sync.Mutex func main() { log.SetFlags(log.Lmicroseconds) log.Println("app start") log.Printf("runtime.NumCPU(): %d\n", runtime.NumCPU()) var cnt, old uint64 var wg sync.WaitGroup wg.Add(tryTimes) go func(wg *sync.WaitGroup) { for { time.Sleep(time.Second) mux.Lock() log.Printf("diff: %d\n", cnt-old) old = cnt mux.Unlock() wg.Done() } }(&wg) go func() { for { mux.Lock() cnt += 1 mux.Unlock() } }() wg.Wait() log.Printf("avg : %d\n", cnt/tryTimes) log.Println("app done") }
1コアだけを空回しするプログラムなので、1000m以下では徐々に性能が上がっていって、1000m以上は指定しても変化がないと予想していた。
次のような結果になった。 グラフには省略したが、 resources.limits.cpuを無指定にした場合も1000mと同程度の値になった。
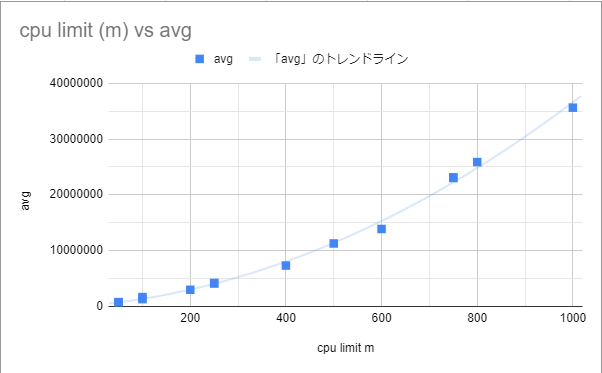
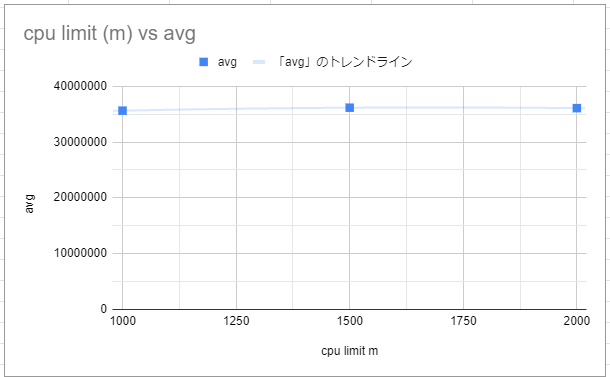
確かに予想通りの傾向にはなったものの、500mと1000mや、400mと800mのようにちょうど2倍だけ割り当てるようなケースでキレイに性能が2倍になるわけではなかった。
1000m未満の場合は「あえてCPUの使用量を制限する」という処理をしないといけないはずだから、その分がオーバーヘッドになってしまい性能が出ないのかなとも思ったが、ちゃんと調べていないので実際の理由は分かっていない。
この傾向が本当にあるとなると、resources.limits.cpuを1000m未満で指定してしまうと一時的にCPUを使いたいようなケースでも思ったよりも性能が出ないということになりそうなので、1000m以上を指定するのが無難そうな気がした。 それか、そもそもlimitsは指定しないのでもいい気がする。